
Simulating Cloud Infrastructure with Terraform
This is a simulation that demos how to use HASH to automatically generate a representation of your cloud infrastructure. It uses a simple terraform.tf.json file (terraform_resource.json) to define and initialize a kubernetes cluster, where incoming requests are handled by short lived pods. The specs for the nodes and the pods are defined in the terraform file and in an accompanying instances.json file, which includes the specifications for different AWS instance types.
Additionally requests are generated according to real-world data. The request distribution was uploaded as a dataset — distribution.csv — and represents the proportion of daily requests received in each hour of the day. Requests are executed as soon as received, unless there are not currently enough compute resources available in the cluster. In this case, the request is queued until adequate resources become available. Compute resources become available when a request completes, or when a new compute node is added to the cluster by the autoscaler.
To modify this for your own cloud infrastructure:
- Convert your terraform plan to terraform.tf.json with the terraform CLI or use an HCL to JSON converter
- Change the deployment_name and the resource_name in init.json to match the ones in your terraform resource file.
- Create a distribution of requests that reflects the real world patterns you want to demonstrate
The parameters controlling this simulation may be tuned through the globals.json file. These parameters are:
requests_per_day: the number of user requests received per day.request_time_seconds: a triangular distribution which specifies the duration of each request run. This distribution is parameterised by amin,modeandmax, in seconds.node_specs: the number ofcpucores and gibabytes ofmemoryin each compute node in the cluster.pod_specs: the number ofcpucores and gigabytes ofmemoryallocated to the pod for each request run.autoscale_bounds: the autoscaler automatically adds and removes nodes in an effort to maintain cluster utilisation between the given bounds. If cluster utilisation exceedsmax_util, then one node is added to the cluster. Similarly, if utilisation drops belowmin_util, then one node is removed from the cluster. At each time step, at most one node will be removed or added.autoscale_delay_minutes: the time delay before which a request to add a node to the cluster is fulfilled. There is no delay to remove a node.initial_num_nodes: the starting number of nodes in the cluster.min_num_nodes: the minimum number of nodes required to be in the cluster at all times.
Each step in the simulation represents a passing of one minute.
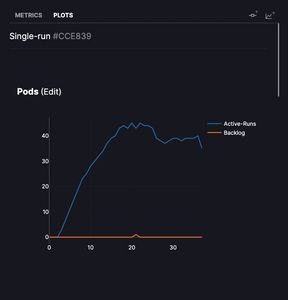
The Analysis tab contains several plots illustrating how the cluster evolves as experiment requests are received and executed.
- Pods shows the number of actively running, and queued requests, at each time step.
- Cluster CPU Usage shows the total number of CPU cores in the cluster and the current utilisation at each time step.
- Cluster Memory Usage shows the total amount of memory in the cluster and the current utilisation at each time step.
- Number of Nodes shows the number of compute nodes in the cluster at each time step.